
Ein paar Details zu aktuellen Störungen
In der letzten und der laufenden Woche gab es bei uns mehrere Ausfälle, bei denen jeweils KVM-Wirte, auf denen wir in der Regel drei bis vier Uberspace-Hosts betreiben, spontan weggebrochen sind. Vorgestern gab es dann noch einen vollkommen bizarren Fuckup auf gleich sieben KVM-Wirten gleichzeitig, der über Stunden zu sehr langsamem I/O auf den betroffenen Systemen geführt hat und dabei nicht nur die direkt darauf laufenden Uberspace-Hosts beeinträchtigt hat, sondern auch die der Failover-Partner nebendran.
Diese Probleme sind uns nicht nur ausgesprochen unangenehm (gerade auch weil diejenigen, die schon länger bei uns hosten, wissen, dass das alles andere als der Normalfall ist), sondern sie stellen uns auch vor große Rätsel. Wir haben leider bisher keine gute Erklärung, sondern stehen dazu sowohl mit unserem Hardwarelieferanten, der Thomas-Krenn.AG, und jener wiederum mit Adaptec, dem Hardware-Hersteller, in engem Kontakt. Dieser Blogpost hier wird insofern leider wenig Erkenntnisgewinn liefern; wir möchten aber gerne so transparent wie möglich kommunizieren, was gerade los ist.
Einmal ist keinmal …
Zunächst fing es mit Ausfällen an. Erstmal einer, giselher, am Abend des 3. Dezember, mit aquila, auriga, cepheus und scorpius als Gästen. Das war blöde genug, kann aber - so ärgerlich das ist - durchaus darunter verbucht werden, dass sowohl der Linux-Kernel als auch die Controller-Firmware Bugs haben können, und schließlich kann ein Stück Hardware auch einfach mal kaputtgehen. Das muss insofern schlicht als einigermaßen normal gelten, dass unter mehreren Dutzend Servern alle paar Monate auch mal einer einfach “spinnt”, und wir betreiben die oben beschriebene Replikation, um in solchen Fällen keine allzu lange Downtime entstehen zu lassen.
… aber zweimal ist zweimal zuviel
Direkt am nächsten Vormittag darauf, am 4. Dezember, hat kurwenal sein Plattensystem, nun ja: verloren. Der Host selbst lief aber noch, nur eben ohne eigenes Plattensystem: Die Replikation sorgt dann dafür, dass die Schreibzugriffe nur noch auf dem Replikationspartner stattfinden (lokal geht ja nicht mehr), und dass auch die Lesezugriffe dann eben nicht mehr vom lokalen Plattensystem aus stattfinden, sondern über’s Netz vom Failover-Partner. Das ist natürlich nicht so performant, aber über eine GBit-Crossover-Verbindung hält sich’s im Rahmen. Wir konnten die Gäste insofern alle noch livemigrieren, so dass kein Ausfall von Uberspace-Hosts zu verzeichnen war. Ein Ausfall am 3. Dezember, ein Ausfall am 4. Dezember … ey, manchmal spielt der Zufall aber echt gegen einen, dachten wir.
Och nö. Echt jetzt?
Wir hatten gerade mal zwei Stunden Ruhe, dann fror am Mittag des 4. Dezember der KVM-Wirt kriemhild ein, mit ara, libra und norma darauf. (Wie inzwischen unschwer zu erkennen sein dürfte, benennen wir unsere KVM-Wirte nach Figuren aus Richard-Wagner-Werken.)
In der übernächsten Nacht, am frühen Morgen des 6. Dezember, verabschiedete sich dann das Plattensystem von gunther, einem weiteren Wirt; hier jedoch noch mit der Möglichkeit, die noch laufenden Gäste ausfallfrei wegzumigrieren. Alles, was dmesg dazu zu sagen hatte (und auch die anderen Vorfälle haben nicht signifikant Brauchbareres geliefert), war:
aacraid: Host adapter abort request (7,0,0,0)
aacraid: Host adapter reset request. SCSI hang ?
AAC: Host adapter BLINK LED 0x5
AAC0: adapter kernel panic'd 5.
Auffällig war, dass alle ausgefallenen KVM-Wirte jeweils Probleme mit dem Plattensystem meldeten, und dass alle jene Server mit einem Adaptec 6405 mit ZMCP (“Zero Maintenance Cache Protection”) laufen. Diese Modelle haben die früher bei uns gern eingesetzten 3ware-Controller mit BBU (“Backup Battery Unit”) ersetzt, und in jüngeren Hosts wiederum arbeiten wir mit Controllern von LSI, die wie die Adaptec-Controller ein ZMM (“Zero Maintenance Module”) einsetzen.
Exkurs: BBU, ZMCP/ZMM, WTF?
RAID-Controller haben in der Regel schön große Caches, damit Schreibzugriffe zunächst durch diesen Cache abgefedert werden können, damit das Betriebssystem schon mal weitermachen kann, während der Controller in Ruhe die Daten auf die physischen Platten wegschreibt. Das ist schön, aber jener Cache ist eben nur RAM: Gibt’s einen Stromausfall, so sind die Daten aus dem RAM halt weg, was ärgerlich ist, denn das Betriebssystem ist ja der Meinung, sie korrekt auf die Platte gebracht zu haben - Dateninkonsistenzen sind da programmiert. Eine BBU löst dieses Problem, in dem sich auf dem Controller neben dem Cache auch eine Batterie befindet, die in der Lage ist, auch bei einem Stromausfall den RAM-Inhalt noch eine ganze Weile zu halten. Neues Problem 1: Batterien haben eine begrenzte Lebensdauer und fallen dann irgendwann aus. Neues Problem 2: Gelegentlich macht der RAID-Controller einen Battery Learning Cycle, bei dem die Batterie einmal komplett entleert und dann wieder geladen wird, primär, um ihre Funktion zu testen und eine Haltekapazität prognostizieren zu können. In dieser Zeit wird dann allerdings der Schreibcache abgeschaltet - und die Performance rauscht in den Keller. Ist also auch nicht so super.
Bei ZMCP/ZMM handelt es sich letztlich um eine Weiterentwicklung: Neben dem Cache, der weiterhin flüchtiger RAM ist, befindet sich hier nun noch ein Kondensator sowie ein Flash-Speicher auf dem Controller. Der Flash ist zwar langsamer als RAM, kann aber Daten eben ohne Strom halten, genauso wie in einem USB-Stick oder einer SSD. Bei einem Stromausfall sorgt der Strom, den der - im Gegensatz zu einer Batterie wartungsfreie - Kondensator vorhält, dafür, dass der RAM-Inhalt des Controllers noch eben schnell auf den Flash-Speicher geschrieben wird. Dort kann er dann im Grunde dauerhaft bleiben, denn dafür ist ja kein Strom nötig.
Diese ZMCP-Module haben uns schon mehr als einmal Ärger gemacht. Zero Maintenance, my ass. In rund einem halben Dutzend Fälle wollte das ZMCP zwar nicht gewartet werden, aber … es war kaputt, mit der Folge, dass der Controller sofort den Schreibcache abschaltet. Gut, halb so schlimm, Gäste auf den Partner migrieren, KVM-Wirt runterfahren, aufschrauben, ZMCP tauschen. Boni kann ein Lied davon singen, weil er die Module dann immer vor Ort im Rechenzentrum austauschen durfte.
Zurück zum Thema
Chris hatte in der Zwischenzeit nach der Feststellung, dass alle ausgefallenen Hosts den gleichen Controllertyp einsetzen, eine Aufstellung gemacht, und dabei festgestellt, dass bei einer Sortierung der Liste nach Seriennummer der Controller alle ausgefallenen Hosts überraschend nahe beieinanderlagen. Er schloss seine Aufstellung mit einem Verweis auf die unmittelbar daneben/dazwischen liegenden Hosts:
Ohne die Kassandra spielen zu wollen, aber wenn joker, brynhild und thelma demnächst Probleme machen, wäre ich nicht überrascht.
Chris’ Rolle als Kassandra funktionierte par excellence: Am frühen Abend des 8. Dezember fiel dann brynhild aus, und damit ara, dorado, lupus und serpens - ja, nochmal ara, den wir nach dem Ausfall vom kriemhild am 4. Dezember extra auf brynhild migriert hatten. Scheißendreck, ey! Das kann’s doch echt nicht sein! Wir gingen langsam auf dem Zahnfleisch, zumal es nach wie vor an brauchbaren Erklärungen mangelte und bis heute mangelt.
Na, noch nicht genug?
Drei Stunden später fiel giselher, der bereits am 3. Dezember ausgefallen war, erneut aus und riss damit erneut auila, auriga, cepheus und scorpius mit sich. BIOS-Version, Controller-Firmware, Linux-Kernel: Alles war nach dem vorigen Ausfall nochmal kontrolliert und auf den neuesten Stand gebracht worden, so wie bei allen anderen Hosts auch. Und trotzdem ein erneuter Crash, der auch diesmal nicht auf defekte Platten zurückzuführen war. Reboot: Controller okay, ZMCP okay, Platten okay. Alles funktioniert wieder einwandfrei. Das ist verständlicherweise die unbefriedigenste Variante: Wenn’s funktioniert und man weiß nicht, warum.
Das Ticket, das wir bei Krenn zum Thema führen, wächst seitdem stetig weiter, Controller-Logs werden ausgewertet, Krenn weist Adaptec zurecht höflich darauf hin, dass ihr Kunde “bereits etwas sensibel” sei. Konkrete Erkenntnisse gibt es leider bisher auch weiterhin nicht; uns liegt allerdings zumindest schon mal die Zusicherung vor, bei einem erwiesenen Controller-Problem unbürokratisch alle betroffenen Controller durch Adaptec austauschen zu lassen, unabhängig vom Garantiestatus. Wir werden sehen, ob dies nötig sein wird (was auch die Frage aufwirft, ab wann ein Controller-Problem als “erwiesen” gelten kann) - erstaunlich ist es aber schon, dass Geräte, die im Abstand von jeweils 1-2 Monaten vor rund 2-3 Jahren angeschafft werden, nun nahezu gleichzeitig Probleme machen - aber dann eben wiederum auch nicht alle davon. Ob melot, tristan, isolde, siegfried, joker oder thelma: All diese Hosts mit den gleichen Controllern aus dem gleichen Seriennummernbereich laufen ohne Probleme.
Öfter mal was Neues
Am 9. Dezember bekamen wir dann noch eine ganz anders geartete Facette zu spüren. Es war kurz nach 14 Uhr, als die erste Load-Warnung bei uns eintraf. So weit, so gewöhnlich: Lastsituationen können vorkommen, dann schaut mal halt nach und klärt, was da los ist. In diesem Fall war bereits an der von Queries überquellenden MySQL-Prozessliste zu erkennen, dass “irgendwas mit dem I/O ist”. Und tatsächlich: Das System, das normalerweise mit I/O-Wait-Werten im Bereich von 2-3% agiert, wies nun einen I/O-Wait von rund 15% auf. Das Interessante dabei war: Die Menge der Lese- und Schreibzugriffe war unverändert; sie dauerten nur plötzlich sehr viel länger. In unserem Munin sah das so aus (oben in blau ist der I/O-Wait eingezeichnet):
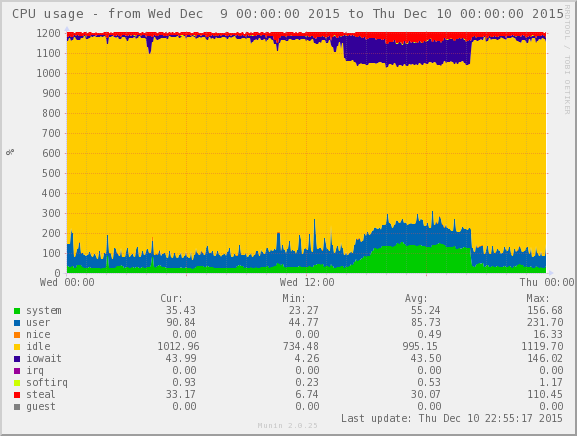
Sowas kann passieren, wenn zum Beispiel ein anderes Gastsystem auf dem gleichen Wirt plötzlich enorm viel Schreiblast generiert. Das war aber schnell geprüft: Das war nicht der Fall; auch die I/O-Lese- und Schreib-Werte für den gesamten KVM-Wirt sahen unverändert aus. Im Grunde genommen wirkte die Situation, als habe der Controller seinen Cache abgeschaltet, als wenn das ZMCP aufgegeben hätte. Nur: Der Controller meldete, das ZMCP sei völlig intakt, und auch der Cache sei aktiv.
Während wir die Situation analysierten, kam die nächste Load-Warnung rein. Und dann noch eine, noch eine und noch eine - und es war kein Ende abzusehen. Am Ende kamen wir auf 34 (ja, vierunddreißig) Uberspace-Hosts mit identischen Symptomen, und jene ließen sich auch klar mit der Hardware in Verbindung bringen, denn entweder hatten alle Gäste eines Wirts das Problem oder aber keiner. Wir haben alles skizziert und konnten nach einer Weile insgesamt 7 (ja, sieben) KVM-Wirte identifizieren, die zeitgleich exakt das gleiche Problem aufwiesen. Dass sich der Effekt von “nur” 7 KVM-Wirten auf gleich 34 Gäste auswirken kann, hängt wie eingangs beschrieben damit zusammen, dass jeder KVM-Wirt nicht nur seine eigenen Gäste betreibt, sondern gleichzeitig Failover-Partner für zwei weitere KVM-Wirte ist, die über separate Crossover-Verbindungen quasi “links” und “rechts” davon angeschlossen sind, sprich, eine Ketten-Architektur, die ohne zentralen Switch und damit auch ohne zentralen Single Point Of Failure auskommt.
Wir haben dann damit begonnen, die betroffenen Gastsysteme - die ja nicht ausgefallen waren, sondern “nur” entsetzlich lahmten - jeweils von einem “schlechten” KVM-Wirt auf einen “guten” KVM-Wirt livezumigrieren und anschließend den “schlechten” KVM-Wirt zu rebooten. Und siehe da: Nach einem Reboot war das Problem … einfach weg und der Controller lieferte wieder die gewohnte Performance; der beste Beleg dafür, dass es sich eigentlich nicht um defekte Hardware handeln kann, denn die bliebe ja auch nach einem Reboot noch defekt. Vielmehr wirkte es eben so, als hätte ein vorgesehener Wartungsjob zu einer festgelegten Uhrzeit sowas wie einen Battery Learning Cycle angestoßen. Nur, dass ein ZMCP sowas eben nicht hat, eigentlich. Und dass die Server sowas in den letzten Jahren nie gemacht haben.
Nur gestern, zu siebt. Wir sind ein bisschen fassungslos.
Die Überschneidungen zwischen den fünf ausgefallenen Hosts und den sieben klemmenden Hosts belaufen sich nebenbei auf lediglich zwei Systeme, brynhild und gunther.
Mein Kollege Boni und ich haben bis nach Mitternacht Gäste entlang der KVM-Kette jongliert, um problematische KVM-Wirte freizumachen und dann die Gäste wieder zurückzuholen, nachdem Chris die Controller-Logs gesichert, nochmal den Update-Zustand von Betriebssystem und Firmware kontrolliert und den jeweiligen Host rebootet hat - was besonders problematisch an zwei Stellen der Kette war, wo zwei “schlechte” KVM-Wirte direkt nebeneinanderlagen, aber: Lief. War nur halt scheiß Arbeit. Anschließend haben wir die Gäste wieder anständig ausbalanciert, so dass beim Ausfall eines KVM-Wirts dessen 3-4 Gäste zum Teil nach links und zum Teil nach rechts failovern können, auf dass die jeweils danebenliegenden Systeme nur rund 50% zusätzliche Last bekommen und nicht gleich 100% - der eigentliche Sinn der Ketten-Architektur.
Fazit, vorerst
Für den Moment ist also alles wieder gut: Alle Systeme laufen, alle Systeme haben aktuelle Kernel, alle Systeme haben aktuelle Controller-Firmware. Und wir haben schon mal heute die “böse” Zeit von 14 Uhr überstanden, ohne dass das I/O-Wait-Problem erneut aufgetreten wäre (lacht nicht, wir hatten etwas Schiss). Nun warten wir ab, die Kommunikation mit Krenn wird laufend weitergeführt, und wir werden sehen, was dabei rauskommt. Dreimal auf Holz geklopft, dass die Hardware-Resets den Hosts gut getan haben und sie jetzt erstmal wieder schnurren.