
Rundumerneuerung unserer Infrastruktur - einmal alles neu bitte!
Wir von Operations arbeiten für euch traditionell eher unsichtbar im Hintergrund, damit eure Uberspaces erreichbar sind und die Kollegen aus der Entwicklung neue coole Features umsetzen können. Meistens ist es eine gute Nachricht, wenn ihr von uns nur wenig hört, denn dann läuft erstmal alles. Heute läuft zwar alles, aber wir wollen euch stattdessen einen Einblick in eine der größten Umstellungen geben, die wir in den letzen Jahren umgesetzt haben.
Veränderungen sind nicht einfach und das galt sowie gilt auch für unsere über die letzten 10 Jahre gewachsene Infrastruktur im Bereich Netzwerk und Virtualisierung. Hier hat sich die Technik in all diesen Jahren nicht viel verändert, auch weil sie, historisch betrachtet, erstaunlich robust war. Allerdings hat sie uns immer weiter eingeschränkt und nur wenig Spielraum für eine Weiterentwicklung und Verbesserung gegeben.
Um das zu ändern, haben wir in den letzten anderthalb Jahren viel geplant und umgesetzt. Dabei hat unser kleines Team aus nur 3 Leuten tolle Arbeit geleistet und es trotz verschiedener Herausforderungen geschafft, die Projekte im Zeitplan fertigzustellen.
So konnten wir dieses Jahr am 11. September mit der ersten VM auf einer völlig neuen Infrastruktur eine neue Ära einläuten, die ihr mit der Migration des ersten U7 Hosts elst am 31.10. auch schon miterleben durftet.

Im Folgenden wollen wir euch daher erzählen, wie dieser Prozess aussah und wie wir an unserem Standort FRA3 eine komplett neue Netzwerk- und Virtualisierungsinfrastruktur aufgebaut haben.
Unsere bisherige Architektur
Das Markanteste an unserer bisherigen Plattform ist die Architektur der VM-Hosts als Kette. So hat jeder VM Host in unserem alten Cluster jeweils eine Kupfer-10G-Verbindung zum nächsten und eine zum vorherigen Partner. Diese Verbindungen werden genutzt, um die DRBD-Devices, also den Speicher der VMs, zwischen jeweils zwei Partnern synchron zu halten und uns so einen schnellen Failover im Fehlerfall zu ermöglichen.
In Richtung Internet, ist jeder VM Host zusätzlich mit 1Gbit/s angebunden. Dabei ist das Netzwerk-Setup sehr statisch und Aspekte wie Uplink und Router wurden von unserem Provider gemanaged und bereitgestellt.
Die Server selbst sind relativ unspektakulär. Sie bestehen aus bis zu vier 6TB HDDs in einem RAID10, 256GB RAM und zwei Xeons mit 10 Kernen und 20 Threads. Die verwenden wir übringens auch weiter, auch wenn wir sie für den neuen Cluster etwas aufgefrischt haben. Auf den Servern selbst lief bisher ein CentOS, welches zusammen mit einem libvirt und QEMU/KVM die Basis für unsere Uberspaces bildet.

Das riecht doch nach Legacy
Die Einschränkungen der alten Plattform waren vielfältig, aber das größte Problem war vermutlich immer die fehlende Flexibilität. So konnten wir, wenn wir zum Beispiel einen VM-Host warten mussten, die VMs immer nur einen Partner weiter schieben. Das wird bei Updates und damit verbundenen Reboots auf Dauer ganz schön nervig. Aber es limitiert uns auch bei der Auslastung der Systeme, die wir so nie über 50% belasten konnten, da wir ja genug Ressourcen für alle VMs des Partners freihalten mussten. Genau so war es ohne größeren Aufwand nicht möglich, die Auslastung der Systeme nachträglich zu optimieren und Uberspaces mit viel und wenig Last optimal zu mischen.
Aber auch der Support und die Entwicklung haben sich Funktionen gewünscht, die wir mit dieser Lösung nicht einfach umsetzen konnten. So mussten die anderen Teams uns immer wieder uns für ziemlich viele Probleme oder Änderungen an den VMs anhauen, die sie mit einer passenden Oberfläche auch schnell selbst umsetzen könnten.
Gleichzeitig war das System nicht wirklich schön zu automatisieren und somit viel manueller Aufwand, denn für Vieles hätten wir zeitaufwändig eigene Lösungen entwickeln müssen. Letztlich hat uns das System aber auch bei der Entwicklung neuer Features eingeschränkt, weil wir zum Beispiel nicht dynamischer mit dem Speicher umgehen konnten.
Das Netzwerk ist die andere Baustelle. Hier haben wir über viele Jahre auf die Erfahrungen unserer Rechenzentrumsbetreiber gesetzt, einfach auch, weil wir weder die Ressourcen noch ausreichendes Know-How im Team hatten. Das hat sich in den letzten Jahren geändert, so dass wir auch hier viel mehr selbst machen wollten und mussten, wenn wir unserer Plattform ein Upgrade verpassen.
Wie sieht die neue Lösung für uns aus?
Von Anfang an war uns klar, dass wir, entsprechend unserer Ziele und Wünsche, wieder eine Lösung auf Open-Source-Basis haben möchten. Außerdem sollte uns die neue Plattform die Flexibilität und eine deutlich einfachere Betreuung bieten, damit wir die Ressourcen in unserem kleinen Team in Zukunft effizienter nutzen können.
Dabei sind wir bei Ceph als Storage-Lösung und Proxmox VE für die Virtualisierung und das Management der VMs hängengeblieben.
Da wir natürlich aber gerne vorher wissen wollten, ob das auch alles so funktioniert wie versprochen, haben wir uns ein Testsetup aus ein paar alten Hosts gebaut und dann über mehrere Monate alles auf Herz und Nieren geprüft. Dabei sind uns auch ein paar Design-Bugs oder Denkfehler aufgefallen, die wir so noch rechzeitig beheben konnten. Die Teststellung ist dabei zu einem kleinen Labor gewachsen, in dem wir unsere Infrastruktur im Kleinen soweit wie möglich nachstellen, um vorab neue Konfigurationen, Software-Versionen oder auch neue Firmware für unsere Netzwerkkomponenten testen zu können.
Eine weitere Umstellung war der Wechsel zu Debian als Unterbau, da dies eine Anforderung des Proxmox ist. Für mich zum Glück nichts Neues, die Kollegen mussten sich aber erst daran gewöhnen, dass sie sich jetzt nicht mehr mit der /etc/sysconfig-Umgebung der Red-Hat-Derivate rumärgern müssen :)
Hardware
Für den produktiven Start mussten wir dann erstmal neue Hardware in Form von drei neuen Servern anschaffen. Die waren notwendig, da die genutzte Software und ebenso unser für Ceph gewünschtes Redundanzlevel mindestens 3 Systeme vorgibt und wir nicht mit einer eingeschränkten Plattform in die Zukunft starten wollten.
Mittelfristig wird der Cluster jetzt immer weiter durch die alten VM Hosts ergänzt, die wir dafür einmal auf den aktuellsten Stand bringen, nachdem wir die darauf laufenden VMs in den Proxmox-Cluster migriert haben. Neben zwei Glasfaser-10G-Netzwerkkarten (auch hier setzen wir auf Redundanz) bekommen die Hosts noch zusätzlich 6 SSDs, zwei für das RAID1 des Betriebssystems und 4 für die Journal-DB und das WAL der Ceph-OSDs. Eine OSD ist dabei in Ceph einfach ein Element auf dem Daten gespeichert werden können.
Das ist notwendig, um euch die bestmögliche Performance für den Speicher bieten zu können, da die HDDs mit ihren doch begrenzten IO-Operationen pro Sekunde hier deutlich an Performance einbüßen würden, wenn wir DB und WAL gleichzeitig auch auf diesen laufen lassen würden.
Netzwerk
Bevor wir den Cluster allerdings umsetzen konnten, musst auch unser Netzwerk umgebaut und aufgeräumt werden. Für die neuen Strukturen konnten wir somit nicht mehr direkt auf die Dienste unseres RZ-Anbieters zurückgreifen, sondern haben das Ganze selbst umgesetzt. Dazu haben wir die alten 1G Kupfer-Switche durch ein neues Glasfaser-basiertes Netz mit redundanten 10G-Routern und -Switchen ersetzt und verwalten jetzt unser Netzwerk komplett selber. Das reicht von unserem eigenen AS über die BGP Sessions mit unserem Upstream Provider bis hin zu den VLANs und den Netzen.
Dabei haben wir versucht wo es möglich ist direkt auf IPv6 only zu setzen, sodass unsere internen Netze, in denen Ceph, Proxmox, die VM Hosts und andere Komponenten miteinander kommunizieren, inzwischen kein IPv4 mehr benötigen. Am liebsten hätten wir das auch gleich für alle anderen Netze gemacht, aber der Support und die Entwickler waren der Meinung, dass ihr damit nicht ganz glücklich wärt :)
Der Umbau war nicht nur notwendig, um für die Zukunft und für neue Ideen gerüstet zu sein, sondern auch, damit das Ceph und der neue Cluster ausreichend Ressourcen haben. Denn mit dem Ceph liegt der Speicher nur noch zum Teil oder sogar gar nicht mehr auf dem VM-Host, auf dem die eigentliche VM läuft. Gleichzeitig brauchen wir das Netzwerk aber auch, um zum Beispiel für ein Update schnell VMs von einem auf einen anderen Host umziehen zu können.
Beim Thema Netzwerk sieht es mit Open Source natürlich anders aus, hier nutzen wir aktuell primär Hardware von UBNT, was bedauerlicherweise mit ein Grund für das Lab ist. Die Erfahrung hat gezeigt, dass Updates und neue Versionen eine gewisse Nachreifzeit benötigen.
Bevor es der ein oder anderen selbst auffällt, die 10G zwischen zwei U7 Hosts könnt ihr leider nicht vollständig ausnutzen, da wir die VMs der Fairness halber auf etwas unter 1Gbit/s limitiert haben.
Der Umzug
Wie eingangs schon erwähnt, konnten wir die erste VM am 11.09. endlich auf den neuen Cluster umziehen. Anschließend folgten immer mehr, vorerst interne Services, um alles ausgiebig zu testen. Nachdem wir dabei keine Probleme feststellen konnten, war es am 31.10. soweit und die ersten U7-VMs konnten umziehen. Inzwischen sind es schon einige mehr und der erste alte VM-Host ist seit Anfang der Woche ebenfalls Teil des Proxmox-Clusters.
Bei den Migrationen, besonders der großen U7 VMs mit ihren 600GB, sind uns dann doch noch Probleme aufgefallen, die wir so während unserer Tests nicht bedacht hatten. Ein entscheidender Punkt war nämlich, dass wir bei den Tests keine tatsächlichen User auf den Systemen hatten. So merkten wir nach den ersten VMs recht schnell, auch durch euer Feedback, dass der gewählte Weg für den Umzug zu lange dauert und zu viele Ressourcen in Anspruch nimmt. Dabei hatten wir den auf den ersten Blick einfachsten Weg gewählt und über ein gemountetes CephFS und via dd Images der VMs erst auf den Cluster befördert, um sie dann zu importieren. Das hat allerdings nicht nur länger gedauert als geplant, sondern auch die anderen VMs etwas beeinträchtigt, da der Ceph-Cluster noch sehr klein ist. Hier wurden somit alle, zu diesem Zeitpunkt 3, Ceph-Knoten parallel außergewöhnlich belastet. Nicht zuletzt auch, weil wir unterschätzt hatten, dass beim Importieren die Images gleichzeitig gelesen und geschrieben werden und das den Durchsatz etwa halbiert.
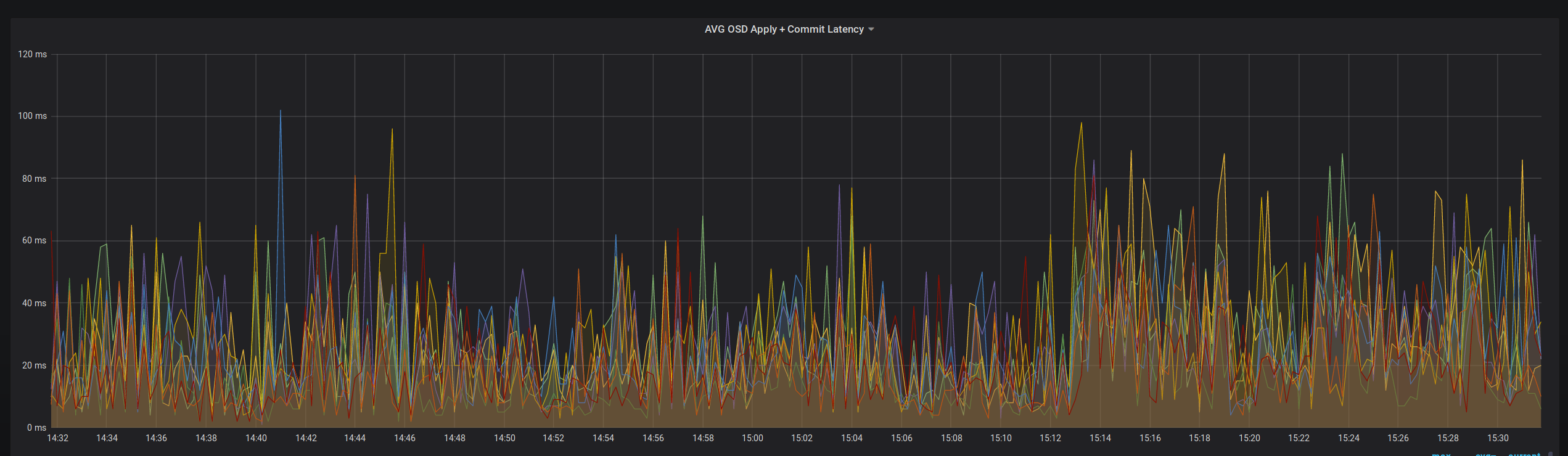
Währen wir die Performance bei den Imports beobachtet haben, ist uns in den Metriken aufgefallen, dass komischerweise die Latenzen, bis ein Datenblock als geschrieben gemeldet wurde, auf zwei der drei Hosts sehr unbefriedingend waren. Nach etwas Debuggen haben wir dann gemerkt, dass auf den zwei langsamen Hosts die RAID-Controller fehlerhaft im JBOD Modus waren und so der Cache der Controller nicht greifen konnte, wie er es zum Beispiel auch in unserem alten Setup macht.
Ein bisschen Recherche hat dann ergeben, dass RAID und Ceph eigentlich eine ganz schlechte Kombination sind (Überraschung!), eigentlich, weil es letztlich doch nicht ganz korrekt ist und ein RAID Controller schon einen Vorteil haben kann, aber eben nur in einer bestimmten Konfiguration.
So sagt die RedHat Dokumentation, die übrigens, im bedauerlichen Gegensatz zur Doku des Projekts selber, während unsere Arbeit immer korrekt war: Dass ein RAID völlig okay und gut ist, solange es ein RAID 0 mit jeweils nur einer Festplatte in diesem RAID 0 ist und der Controller Cache durch eine Batterie oder anderweitig gepuffert ist. Genau das ist der Fall bei uns. JBOD wird hingegen nur für größere Speichersysteme empfohlen die deutlich größer sind als unsere normalen Systeme.
Problem erkannt und jetzt mit dem vierten System im Cluster auch behoben. Dazu haben wir jeweils eines der betroffenen System evakuiert. Dann mussten wir die alten OSDs löschen, die Controller-Konfiguration umstellen und die OSDs anschließend wieder neu anlegen. Dank dreifacher Redundanz kein Problem und der Rebuild lief im Anschluss auch ohne Performanceinbußen. Das Ergebnis kann sich sehen lassen, die Latenzen haben sich massiv reduziert und das ohne Downtime der Gäste:
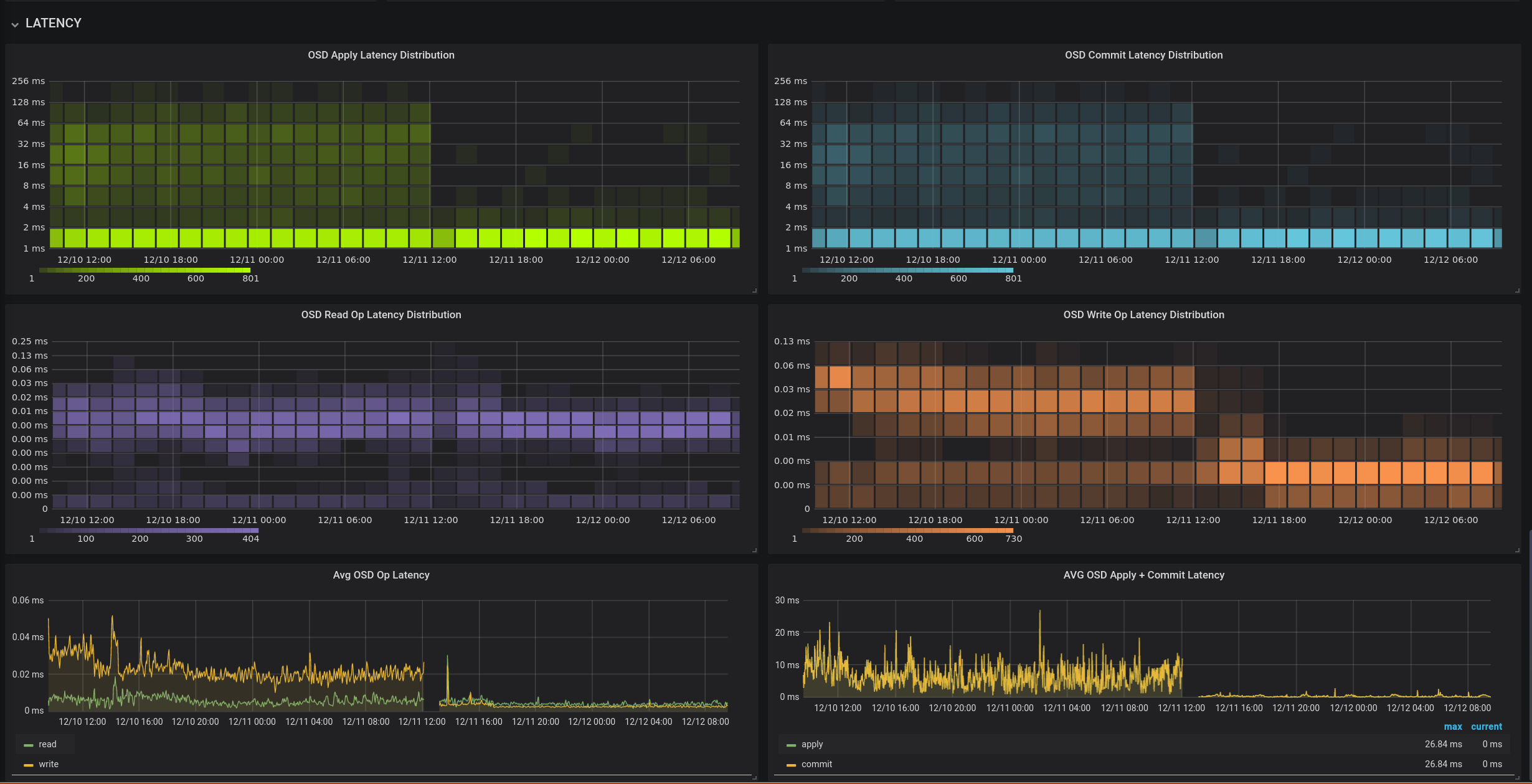
Um jetzt noch das Problem mit den mehrfachen Kopiervorgängen zu beheben, haben wir uns entschieden, in Zukunft die RBD-Devices (Rados Block Device) direkt auf den alten VM-Hosts zu mounten und dann dort per dd die Daten zu kopieren. Das spart nicht nur das Importieren, ist somit um ca. 60% schneller und damit mit weniger Downtime verbunden, sondern ermöglicht uns auch eine etwas genauere Steuerung der Ressourcen, die auf dem Ceph für den Prozess benötigt werden.
Aussichten
Die Aussichten für die nächsten Monate sind spannend, denn es steht nicht nur die Migration aller übrigen Uberspace-VMs am Standort FRA3 auf den neuen Cluster auf dem Programm. Wir werden uns auch mit den Kollegen aus der Entwicklung zusammensetzen, um mit diesen zu besprechen, welche neuen Features wir mit der neu gewonnenen Flexibilität jetzt endlich realisieren können. Ein sehr heiß gehandeltes Feature, das bei uns auch schon lange auf der Liste steht, ist, euch bei Bedarf mehr Speicher anbieten zu können. Es bleibt also spannend und freut euch schon mal auf tolle Neuerungen im nächsten Jahr!
Header-Bild: CC-BY Leah