
Wie plötzlich alles langsam wurde
Einige von euch werden es mitbekommen haben, letzte Woche gab es bei uns einige Probleme. Die Kollegen waren am rotieren und suchten mit Hochdruck nach einer Lösung, denn im Support gingen plötzlich sehr viele Anfragen ein, weil manche U7 Hosts sehr langsam waren. Ganz plötzlich war es allerdings nicht, wir hatten schon auf dem Schirm, dass die Performance nicht ganz so ist, wie wir uns das wünschen würden, aber mit einem mal wurde es deutlich kritischer. Wir hatten eine Grenze erreicht.
Das Problem ist inzwischen behoben und die Performance sollte wieder wie von euch gewohnt sein. Trotzdem überlegen wir natürlich permanent, wie wir eure Uberspaces schneller machen können, ohne dass uns unser Preismodell auf die Füße fällt.
Was war passiert?
Wie ihr vielleicht wisst, migrieren wir kontinuierlich U7 VMs auf unseren neuen Cluster. Dieser Cluster nutzt nicht mehr DRBD und LVM als Storage sondern Ceph. Die Umstellung auf einen verteilten Storage bietet uns dabei viele Möglichkeiten, die wir vorher nicht hatten. Zum Beispiel das beliebige Migrieren von VMs zwischen unseren VM-Hosts. Es macht Dinge aber natürlich auch komplexer.
In den meisten unserer Hosts stecken die gleichen HDDs, das ist für Ceph auch wichtig, da man vereinfacht sagen kann, das Ceph ist nur so schnell wie seine langsamste Platte. Die Realität ist natürlich deutlich komplexer, aber für den Moment reicht uns diese Annahme.
Inzwischen sind wir bei unserem 7. Proxmox Knoten angekommen und bisher hatten wir keine Probleme. Dachten wir zumindest. Letzte Woche kam es dann sehr schnell zu größeren Problemen und wir wollten natürlich schnell wissen, was los ist. Unsere Graphen haben aber auf den ersten Blick keine unmittelbare Verschlechterung der Latenzen oder IOPS gezeigt. Wir waren erstmal ratlos.
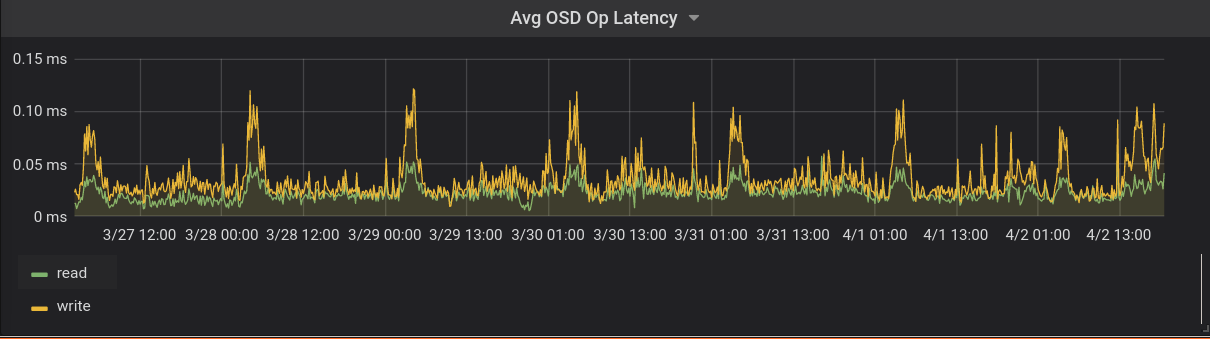
Nach einigem Debuggen der Kollegen - ich war gerade in Urlaub - haben wir festgestellt, dass es insbesondere 4 OSDs (vereinfacht Festplatten) sind die uns durch sehr große Latenzen Probleme machen und alle Stecken im gleichen Host. Das war verdächtig. Daraufhin haben wir alle möglichen Hardware Parameter auf dem Host geprüft, konnten allerdings einfach keine Probleme identifizieren. An dem Platten-Typ, konnte es eigentlich auch nicht liegen, da wir diese auch in anderen Hosts verbaut haben, die das Problem nicht zeigen.
Was die Situation an dieser Stelle schwierig macht ist, dass Ceph (wieder vereinfacht) davon ausgeht das größere Platten auch schneller sind und sich beim Lesen auf eines der drei Replika festlegt. Unschön, wenn das dann unsere problematischen Platten sind :(
Dadurch wurde für euch alles langsam, weil viele der IO-Operationen diesen Flaschenhals passieren mussten. Als uns klar war, dass wir das Problem lokalisiert hatten, haben wir uns unsere Graphen auch noch mal genauer und vor allem für einen größeren Zeitraum angeguckt. Genauer gesagt seit dem der betroffene Host Anfang März dazu kam. Und was soll ich sagen, man sieht den Anstieg der Probleme in den letzten Wochen.
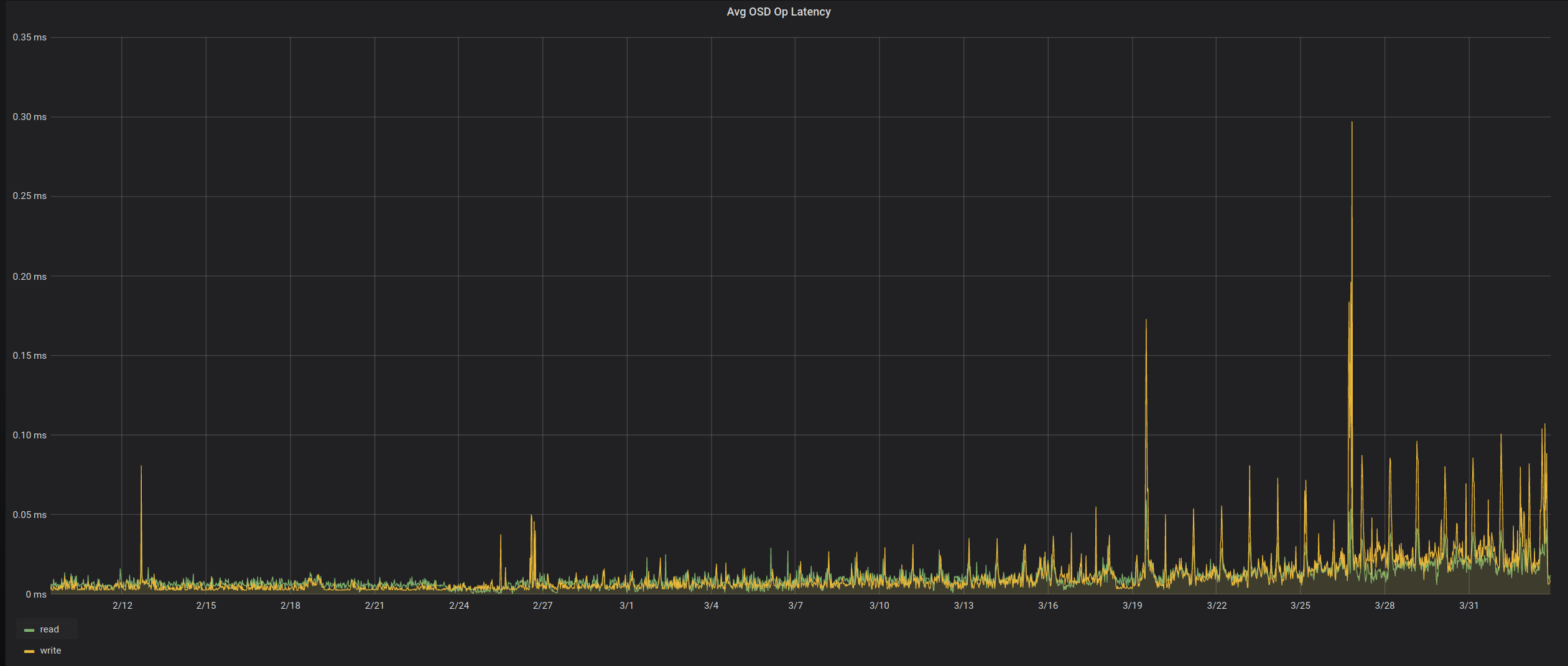
Nun wollten wir etwas tun, die Platten direkt zu tauschen war erst mal keine Option, den sie waren ja grundsätzlich in Ordnung, nur eben nicht optimal zum Lesen. Zum Glück hat Ceph hier eine einfach Möglichkeit den automatischen Algorithmen etwas auf die Sprünge zu helfen. So haben wir die Priorität der betroffenen Platten reduziert, sodass sie nicht mehr zum lesen verwendet werden und siehe da, kurze Zeit später war unser Problem behoben.
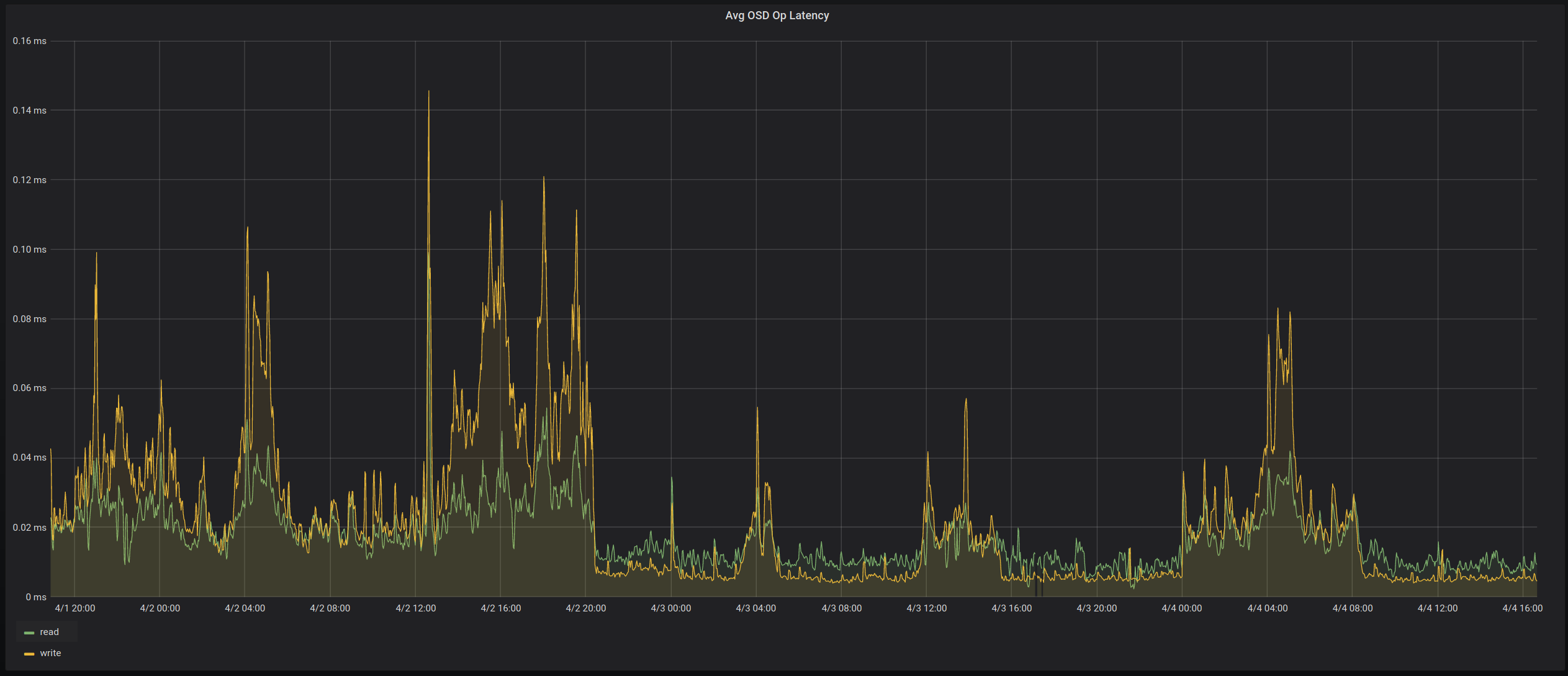
Während dem Debugging haben wir noch viel Weiteres über Ceph gelernt und konnten so einige weitere Parameter anpassen, die zum Beispiel lastintensive Operationen wie das Deep-Scrubbing betreffen. Außerdem arbeiten wir dran kritische Komponenten wie zum Beispiel die Datenbanken in naher Zukunft auf deutlich schnellere SSDs auszulagern.
Das wars auch schon mit diesem kurzen Einblick und bleibt neugierig.