
U7 Storage Performance: Update
Im letzten Monat war die Storage-Performance von Uberspace 7 bzw. unserem Ceph Storage Cluster nicht so, wie wir uns sie vorstellen. Wir haben in den letzten Wochen mehrere Maßnahmen gesetzt und können nun - endlich! - Erfolg vermelden. Danke für’s Durchhalten!
Was bisher geschah
… könnt ihr im Blogpost “wie plötzlich alles langsam wurde” nachlesen. Kurz: um den 9. April rum war alles sehr langsam. Nach dem damaligen Fix verbesserte sich der Zustand von “unbrauchbar” zu “erträglich”. Zum erklärten Ziel “schnell” haben wir’s damit aber noch nicht geschafft.
Einschub: IOPS
Im folgenden Text ist ganz oft von IOPS die Rede. Es wissen ganz sicher nicht alle von euch, was es damit auf sich hat. Wer’s weiß, kann diesen Punkt überspringen.
IOPS sind “input/output operations per second”, also wie von man von einem Storage-Device lesen oder schreiben kann. Gemessen aber nicht wie Netzwerk-Geschwindigkeiten in MBit/s oder GBit/s sondern in der Anzahl der Operationen: “lies mal hier, dann schreib da und, übrigens, hier auch noch lesen” sind dann drei Operationen, (fast) egal wie viele Daten tatsächlich geschrieben wurden.
Das ist wichtig, weil Festplatten aus sich drehendem Metall, wie wir sie hier haben, sehr empfindlich negativ auf viele kleine Anfragen reagieren: Einmal die ganze Platte von vorne bis hinten lesen geht ganz gut, 1.000 kleine Stückchen wild durcheinander lesen nicht so.
und nu?
Da wir unsere Platten nicht magisch schneller bekommen, lag unser Hauptaugenmerkt darauf, die Last reduzieren. Denn je weniger wir auf den Storage zugreifen, desto mehr Kapazität und Geschwindigkeit ist für die eigentliche Aufgabe vorhanden: Eure Webseiten und Apps.
Wir sind also in uns gegangen und haben an vier Orten ordentlich IOPS gespart, Dinge auf SSDs geschoben oder anderweitig optimiert. Das Ergebnis kann sich durchaus sehen lassen - mehr dazu aber später mehr.
systemd-journald & yum/rpm
Neben euren Apps hat die Storage-Performance natürlich auch direkten Einfluss auf unsere Arbeit. Am stärksten zu spüren war das im OnCall und beim Rollout neuer Versionen. Die Kolleginnen in der Bereitschaft waren unglücklich, weil ein journalctl-Aufruf gerne mal Minuten gedauert hat; die Entwicklungsabteilung jauchzte, weil ein einfaches yum info nginx erst nach drei Minuten “jup, is da.” zurückmelden konnte. Beides, weil die Befehle viel zu lange brauchten, um die entsprechenden Daten von der Platte zu kratzen. Das verzögert unsere Arbeit und damit neue Features und schnelle Fixes für euch.
Initial haben wir also die Verzeichnisse /var/log/journal, /var/lib/{rpm,yum} und /var/cache/yum auf SSDs gepackt. Erledigt hat das ein kleines Ansible-Playbook vollautomatisch:
- name: migrate journald onto SSD
tasks:
- name: check that the bind mount is not present
command: # omitted for brevity
- name: rsync journal data onto SSD
synchronize: # omitted for brevity
- name: stop journald
systemd: name={{ item }} state=stopped
with_items: ["systemd-journald.socket", "systemd-journald.service"]
- name: rsync journal data onto SSD
synchronize: # omitted for brevity
- name: move old directories away
command: mv --no-clobber /var/log/journal /var/log/journal.before_ssd_move
- name: bind mount /var/log/journal to /ssd/var-log-journal
mount: # omitted for brevity
- name: start journald
systemd: name=systemd-journald.socket state=started
- name: check that journal still works
shell: journalctl -n1 | wc -l | grep 2
Nachdem wir so auf alle Hosts in Kleingruppen das Journal auf SSDs umgezogen hatten, war auf den SSDs auch direkt mehr Schreiblast zu sehen:
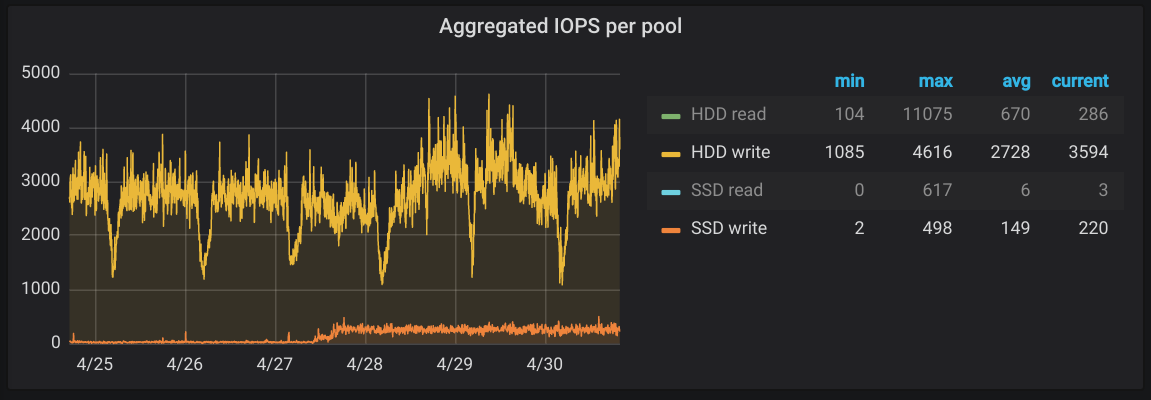
- Der große Gewinn, was die allgemeine Performance angeht, war’s aber nicht. Die
journalctl-,yum- undrpm-Befehlen waren aber sehr viel schneller, so dass die folgende Arbeit weitaus flotter von der Hand ging.
MySQL
Viele voneinander unabhängige Daten, kleine, fast zufällige Schreib- und Lesezugriffe und außerdem recht anfällig für Storage-Latenz: unser MySQL bzw. jede Datenbank ist ein perfekter Kandidat für SSDs.
Nachdem wir also dank schnellem journalctl und yum wieder ordentlich arbeiten konnte, haben wir uns daran gemacht, eure Apps wieder schnell zu machen. Ein exemplarisches WordPress verbringt die meiste Zeit seines Request-Cycles damit, Inhalte aus der Datenbank zu holen. Der PHP-Code liegt im OPCache, die Bilder womöglich schon im Cache des Clients. Wenn wir also die DB auf SSDs schieben, sind automatisch auch viele Applikationen schneller. Außerdem sind die damit frei gewordenen IOPS für andere Apps verfügbar, so dass sie auch davon profitieren.
Den Umzug inklusive ein paar technischer Schmankerl konntet ihr übrigens live im Fediverse auf unserem Mastodon-Account verfolgen. Dort tooten wir in Zukunft auch andere Details oder Eindrücke, die nicht wichtig genug für die großen Accounts oder substantiell genug für’s Blog sind.
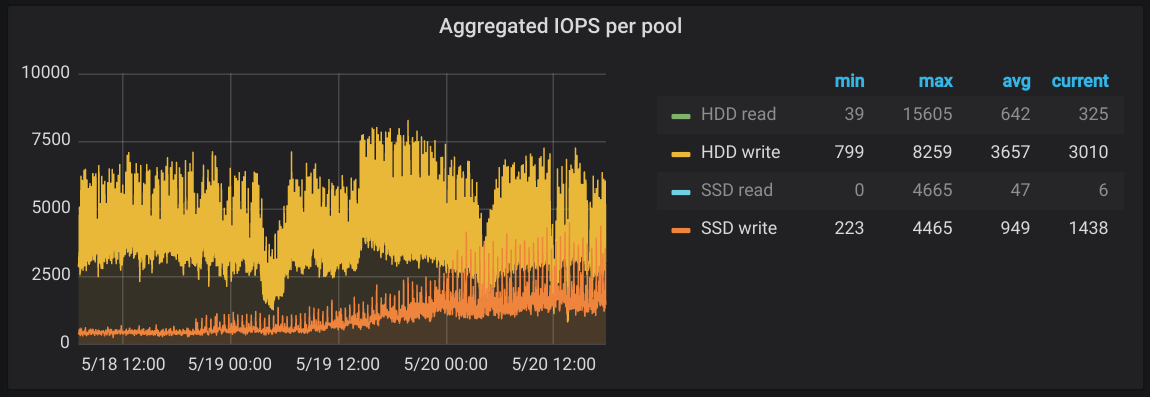
Am 18.5. haben wir angefangen, Host für Host MySQL auf SSDs umzuziehen. Im Graphen sieht man auch deutlich, wie von da an die orange SSD-Write-Linie immer weiter nach oben klettert. Die gelbe Linie der HDDs bleibt aber auf dem selben Niveau. Wir haben den Platten also etwas Last abgenommen, die wurde aber sofort von anderen Anfragen gefüllt, so dass immer noch keine echte Luft nach oben da war.
Nachdem alle Umzüge abgeschlossen waren, hat uns in der Nacht darauf um 4:30 Uhr unser Monitoring unsanft aus dem Bett geholt. Wir haben da nämlich ein kleines Detail übersehen. Mehr dazu aber auf Mastodon. (hint! hint! clickbait! clickbait!).
(Diese und die erste Änderung betreffen die 59 (von 85) U7-Hosts, die bereits im neuen Cluster und damit auf dem Storage-Cluster liegen. Wenn sich bei deiner MySQL-Performance als nichts getan hat, liegt es daran. Wir migrieren laufend U7 Hosts, so dass bald alle dort zuhause sein werden.)
qmail-config.service
Tja, und der Gewinner ist unser geliebtes qmail. Intern schieben wir sehr gerne die Schuld qmail zu - unser Universalsündenbock, quasi. In diesem Fall dürfen wir uns aber ganz offiziell selbst den Schuh anziehen.
Etwas Kontext: qmail hat, zusammen mit ein paar anderen Mailservern, die Eigenschaft, Mails, wenn sie denn lokal zugestellt werden können, auch lokal zuzustellen. Wenn also “isabell.org” für eine lokale Userin eingetragen ist, bekommt sie auch die von anderen Usern auf dem gleichen Host generierten Mails für “isabell.org” - egal was im MX für die Domain steht. Bei ihrer Domain ist das kein Ding und so gewollt. Sollte sich Isabell aber als Angreiferin verstehen, kann sie einfach uberspace mail domain add posteo.de ins Terminal tippen und - tada! - alle Mails, die eigentlich zu Posteo sollten, landen jetzt bei ihr. Unpraktisch.
Auf Uberspace 6 haben wir als Abhilfe zwei Qmail-Instanzen betrieben: qmail und qmail-relay. Die erste war mit den User-Domains gefüttert und hat lokal Mails verteilt, die zweite kümmerte sich darum, Mails ins Internet zu verteilen und wusste nichts von lokalen Domains und Usern. Dadurch ergeben sich zwei unterschiedliche Mail-Queues und Isabell kann keine Posteo-Mails mehr erhalten.
Auf Uberspace 7 war uns vor vier Jahren der Zirkus mit zwei Qmail-Installationen aus mehreren Gründen zu unpraktisch. Stattdessen checken wir hier, ob der MX-Record auch wirklich auf den Host zeigt, auf dem die Domain aufgeschaltet ist: bei dig MX isabell.org muss also 10 tuttle.uberspace.de. rauskommen, damit “isabell.org” überhaupt in der Mailserver-Config eingetragen wird. Im Nachhinein gesehen hat uns das mehr Nachteile als Vorteile gebracht, aber das ist ein anderes Thema.
DNS-Records ändern sich alle Jubeljahre mal, also müssen wir auch alle Jubeljahre nachgucken, ob denn der MX noch (oder schon) passend ist. Weil das in unserem Setup an einen anderen qmail-Task geknüpft ist, läuft der Check recht häufig: alle 30 Sekunden. Der tatsächliche Record-Check wird pro Domain allerdings nur alle paar Stunden ausgeführt, um die anderen DNS-Server nicht so zu nerven.
Was uns das Bein gebrochen hat, sind nicht die Hand voll DNS-Abfragen, sondern das Status-Reporting dazu. Wir haben nämlich in den Anfängen der U7-Entwicklung vor vier Jahren in jugendlichem Leichtsinn folgenden Code produziert:
for domain, dcfg in user.mail_domains.iteritems():
try:
if should_check(dcfg.dns_valid, dcfg.last_check) or force:
dns_valid = domain_has_valid_mailservers(domain)
_set_domain_key(user, domain, 'last_check', timestamp)
_set_domain_key(user, domain, 'dns_valid', dns_valid)
_set_domain_key(user, domain, 'error', False)
_set_domain_key(user, domain, 'error_msg', None)
except Exception as ex:
_set_domain_key(user, domain, 'last_check', timestamp)
_set_domain_key(user, domain, 'dns_valid', False)
_set_domain_key(user, domain, 'error', True)
_set_domain_key(user, domain, 'error_msg', str(ex))
Die unschuldige Funktion _set_domain_key(user, domain, k, v) öffnet eine Datei, liest sie komplett ein, schreibt eine Kopie komplett neu und überschreibt dann atomar das Original. Im Worst-Case passiert das 4 Mal pro Domain, was rund 1.200 Aufrufe pro Durchlauf bedeutet. Alle 30 Sekunden. Auf 90 U7-Hosts. Dass das Mist ist, müssen wir nicht diskutieren.
Uns ist etwas unklar, warum uns der Code erst jetzt die Füße fällt. Im Großen und Ganzen sieht die Konstruktion seit dem Launch von U7 2016 genau so aus wie heute auch. Damals hat sich allerdings niemand über die Storage-Performance beschwert - ganz im Gegenteil, war ziemlich flott. So oder so: der Code ist Mist und muss weg.
Der initiale Fix war einfach: schreib die Datei pro User nur ein Mal, nicht vier mal pro Domain. Das macht dann nur noch ~150 statt 1.200 Aufrufe pro Host. Der Impact auf die IOPS kann sich sehen lassen:

Ehrlich gesagt ist uns unser damaliges Vorgehen schon etwas peinlich. Aber, was soll man machen: live and learn. Wir werden in Zukunft garantiert auch bei Code-Reviews neuer Scripts genauer darauf achten, wie viel wir wie oft auf die Platte schreiben.
Langfristig möchten wir, auch wegen der kurz angeschnittenen Probleme damit, wieder weg vom DNS-Checker. Für’s Erste ist dieser Fix aber mehr als gut genug.
Ausblick
Auch wenn die Performance auf U7 jetzt schon ganz schick ist, möchten wir nicht an diesem Punkt aufhören. Um’s noch etwa flotter zu gestalten, stehen im Moment noch drei Punkte auf unserer Liste der möglichen Verbesserungen.
Cronjobs
Ganz viele von euch haben Cronjobs, die auf */5*, */10, */15, oder einem anderen Vielfachen von 5 lauschen. Das will zum Beispiel eine Nextcloud so. Diese Jobs sind notwendig, produzieren aber folgendes, unschönes Pattern auf unserem Storage:
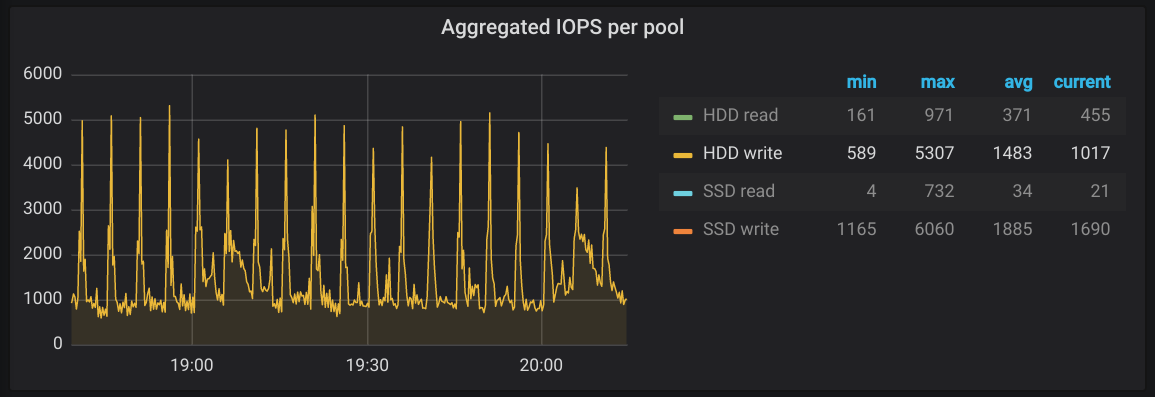
Wenn wir die Cronjobs dazu bewegen können, sich etwas mehr zu verteilen, wären alle etwas früher fertig und unser Storage müsste nicht alle 5 Minuten einen Sprint hinlegen. Bei einigen Crond-Implementierungen, zum Beispiel dem von CentOS eingesetzten cronie, kann man das mit der Variable RANDOM_DELAY steuern. Alternativ oder zusätzlich dazu haben auch mehrere von euch vorgeschlagen, statt eines crond doch zwei oder mehr pro Host zu betreiben oder die IOPS der Cronjobs zu beschränken.
Unser Experiment zu RANDOM_DELAY war leider bisher erfolglos, die anderen Ansätze haben wir noch nicht ausprobiert. Wir sind aber dran; stay tuned.
Deep Scrubbing
Ein weiterer Aspekt, der sich nicht zu knapp auf die Performance des Plattensystems auswirkt, ist das sogenannte “Deep Scrubbing”.
Wir speichern bei Ceph alle Daten redundant: jeder Datenblock ist dreimal vorhanden. Nun schreibt man im produktiven Betrieb natürlich immer alle drei Replika, also auf drei verschiedene Disks, aber man liest immer nur von einer. Abweichungen zwischen den Daten fallen insofern nur auf, wenn man explizit alle drei Replikas vergleicht. Und genau das tut “Deep Scrubbing”: es liest früher oder später jedes Byte von der Platte, vergleicht es mit den anderen Replikas und nimmt gegebenenfalls Reperaturen vor.
Das ist also eine gute Sache; man will das haben. Auf der andere Seite bedeutet das eben auch, dass alle auf den Disks abgelegten Daten regelmäßig gelesen werden müssen. Das kostet Performance - und das leider nicht zu knapp.
Nun gestaltet sich das das Tuning dieses Prozesses für uns leider schwierig. Es gibt zwar Parameter an denen wir drehen können, jedoch ist das Feedback, das uns Ceph gibt relativ binär: hab’s schnell genug geschafft (oder eben nicht). Letzteres gilt es natürlich zu vermeiden.
Mit einem künftigen Ceph-Release wird erwartet, dass bessere Messwerte bereitstehen, die wir in unser Grafana-Dashboard integrieren können. Wir haben daher das Thema auf den Zeitpunkt vertagt, wo wir statt blindem Herumprobieren-und-schauen-was-passiert tatsächlich Parameter ändern und die Änderungen verlässlich messen können, um auf dieser Basis vernünftige Entscheidungen treffen zu können.
externes MySQL
Unsere MySQL-Instanzen liegen auf dem selben Host wie die Userdaten, der Webserver und die User-Services. Das spart zwar eine irrelevante Millisekunde Zugriffszeit, sonst hat dieses Setup aber in der Praxis nur Nachteile. In Zukunft würden wir gerne, so wie alle anderen auf dem Planeten das schon machen ;), MySQL in eigene VMs packen, die dann unabhängig von den U7-Hosts laufen. Dort können wir dann auch speziell auf die Bedürfnisse einer Datenbank eingehen und müssen nicht die Komponenten gegeneinander aufwiegen. Wenn’s klappt, sollte das einen weiteren Bonus an Geschwindigkeit und einen großen Bonus an Stabilität bringen.
SSDs für alle und alles! (Spoiler: leider nicht.)
Eine oberflächlich triviale Lösung wäre es natürlich, einfach alle Daten auf SSDs zu packen. Technisch gestaltet sich das schwieriger, weil wir dazu alle Bleche anfassen müssten und dort gar keinen physischen Platz für zusätzliche SSDs haben. Würden wir aber auch irgendwie auf die Rehe bekommen. Was wir nicht auf die Reihe bekommen ist die XX.000€-Investition, die ein paar Hundert TB plus Redundanz gute Datacenter-SSDs bedeuten würden. Die können wir uns nicht mal eben so aus dem Ärmel schütteln.
Langfristig würden wir natürlich gerne dort hin, mittelfristig wird sich da aber leider nichts tun, so sehr wir es auch wollen.
Fazit
Unsere HDDs haben wir jetzt - endlich - entlastet bekommen. Damit ist alles von einem npm install bis hin zu euren Nextclouds (wieder) schön schnell. Als Bonus liegen die MySQL-Daten jetzt auf SSDs, was einen spürbaren Boost an Geschwindigkeit für Webseitenbesucherinnen bringt.
Wir wünschen also fröhliches, schnelles Weiterhosten! :)
Header: CC-BY https://www.flickr.com/photos/nostri-imago/5156850545