
U7 Storage Performance: Update 2 + Bonusfolge
Drei Monate ist unser letzter Beitrag zum Thema U7 Storage Performance her - Zeit für ein Update. Viel hat sich getan und es wird sich noch viel mehr tun: Am Ende des Artikels haben wir eine tolle Ankündigung für euch ;)
Rückblick
Dieser Artikel ist eine Fortsetzung unseres letzten Updates von Ende Mai zum Thema U7 Storage Performance. Die dort beschriebene Auslagerung von MySQL, systemd-journald, yum und weitere Bugfixes haben bereits eine große Verbesserung gebracht, besonders weil die Daten aus euren Datenbanken nun viel viel schneller verarbeitet werden können. Das hat uns eine kurze Verschnaufpause gebracht, in der wir natürlich trotzdem weiter an Verbesserungen gearbeitet haben. Das ist aber leichter gesagt als getan.
Status
Aktuell ist unser neuer Proxmox und Ceph basierter Cluster fast fertig ausgebaut. Gleiches gilt für die Migration der U7 VMs: davon sind inzwischen etwa 85% von der alten Infrastruktur migriert und viele Neue angelegt worden. Da uns die aussprechbaren Kometen langsam ausgehen, gibt’s ein neues Namensschema: Monde.
Damit sind wir an diesem Standort auch an unserem Limit angekommen, mehr geht weder bei Strom, Klima noch beim Platz in den Racks. Daher kommt bald ein weiterer Cluster hinzu. Das heißt natürlich nicht, dass wir hier fertig sind, aber dazu später mehr.
Feuerwehr 👩🚒
In den letzten Wochen kam es leider wieder zu mehr Problemen und damit auch öfter zu Einsätzen unseres On-Call-Notdienstes, mit dem wir für euch rund um die Uhr sicherstellen, dass Ausfälle möglichst kurz bleiben und Probleme ebenso schnell behoben werden.
Bonusfolge
Ein Fall, der nicht ganz in die Reihe passt, aber für euch sicher spannend ist, ist der komplette Ausfall unseres Clusters vor ein paar Wochen. Das lag allerdings nicht am Storage, sondern am Hochverfügbarkeitsfeature von Proxmox. Wir wissen leider bis heute nicht genau was das Problem ausgelöst hat, können den Ablauf aber wie folgt rekonstruieren: Um kurz vor 13 Uhr haben wir einen unserer Cluster Knoten auf die aktuellste Version gehoben und ein paar Minuten später hat sich der gesamte Cluster automatisch neu gestartet.
Was war passiert? Auf unseren Hosts im Cluster läuft der sogenannte HA-Manager. Dieser kümmert sich darum, dass VMs immer laufen und bei Bedarf auf einer anderen Maschine automatisch neu gestartet werden. Bei solchen Systemen muss immer das so genannte Split-Brain Szenario ausgeschlossen werden: Die Situation, dass zwei unabhängige Teile des Clusters laufen und davon ausgehen, dass die andere Hälfte weg ist und sie jetzt für alles zuständig sind. Zweimal die gleiche VM… keine gute Idee.
Um das zu verhindern, gibt es das Quorum, hier sprechen sich alle Hosts ab wer gerade zum Cluster gehört. Wenn ein Host aufgrund eines Fehlers aus diesem rausfällt und sein Quorum verliert, wird das “Fencing” aktiv. Das ist eine Technik, die im Fehlerfall den defekten Host automatisch rebooted um sicherzugehen, dass er sich nicht in einem problematischen Status befindet. Genau dieses Fencing wurde bei uns aktiv, und zwar zeitgleich auf allen Hosts im Cluster… auch keine gute Idee.
Warum das passiert ist können wir nicht sagen. Sowohl bei früheren, als auch späteren Updates ist das Problem nicht aufgetreten. Genau so war das Netzwerk bei Weitem nicht ausgelastet und die Logs haben auch nichts Genaueres verraten. Hier müssen wir uns leider mit einem schlichten “Wir wissen es nicht” zufriedengeben und hoffen, dass das nicht wieder passiert. Aktuell überlegen wir, das HA Feature bis auf Weiteres zu deaktivieren, wir nutzen es im aktuellen Betrieb eh nicht.
Storage
Aber zurück zum Storage. In den letzten Wochen habe die Probleme bei uns leider wieder zugenommen und wir mussten öfter aktiv werden. Dabei, das könnt ihr von außen ja leider nicht sehen, sind es fast immer neue Probleme mit denen wir uns auseinandersetzen. Letztlich müssen wir uns da eingestehen: Für uns ist das System neu und wir haben sehr viele Vorteile dazu gewonnen, aber es ist eben auch ein komplexes System. Insbesondere Ceph lernt man nicht mal so gerade eben mit all seinen Facetten kennen. Und wenn der Cluster nicht mehrere hundert oder tausend Platten umfasst, bringt das eigene Herausforderungen mit sich. Das bedeutet auch für uns viel lernen und das permanent. Wir geben unser Bestes!
Hinter den Kulissen haben wir in den letzten Wochen unser Monitoring immer weiter ausgebaut und an die häufigsten Probleme angepasst, sodass wir nebenbei immer schnell im Blick haben, ob es irgendwo Probleme gibt und entsprechend nachsteuern können. Das sieht dann zum Beispiel so aus:
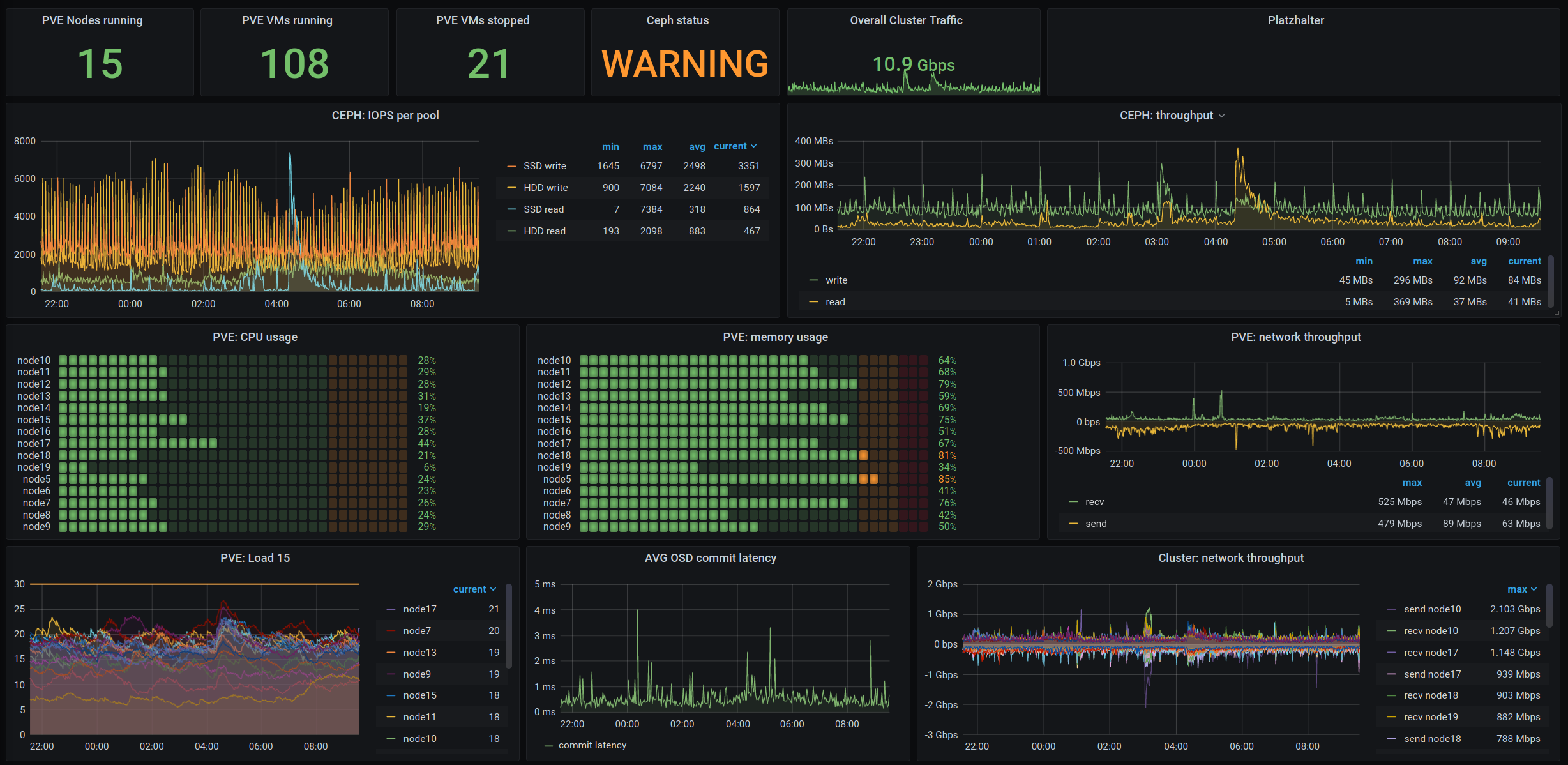
Gleich eine kleine Anmerkung, die Warnung für das Ceph kommt nur daher, dass gerade aufgrund von Wartungen nicht alle Deep Scrubs durchgelaufen sind. Was genau das ist, haben wir euch im letzten Artikel schon mal zusammengefasst. Ein echtes Problem ist das allerdings nicht.
Ein erster Schritt die Probleme der letzten Zeit in den Griff zu bekommen war, dass wir die VMs auf unserem Cluster besser verteilt haben. Nicht jede VM erzeugt gleich viel Last und selbst die schwankt über den Tag deutlich. Was dabei sehr statisch ist, ist der zugewiesene RAM, also haben wir uns beim Verteilen der VMs am Anfang darauf fokussiert, das war aber nicht immer eine gute Idee.
Dank besserem Monitoring haben wir jetzt auch die Auslastung der Virtualisierungs-Hosts und damit unter anderem auch die CPU-Last der VMs deutlich stärker und über den Tagesverlauf hinweg mit einbezogen. Das sorgt dafür, dass wir inzwischen einen viel gleichmäßiger ausgelasteten Cluster haben, der weniger Engpässe und damit weniger Probleme hat.
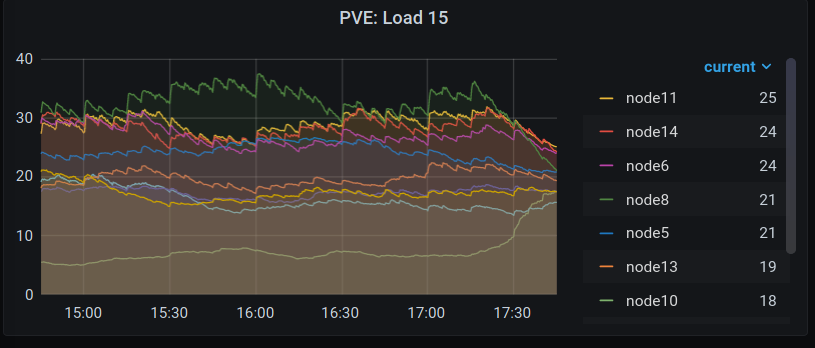
Diese Anpassungen an unserem Monitoring machen es uns auch leichter VMs und Userinnen zu identifizieren, deren Prozesse unabsichtlich zu viele Ressourcen verbrauchen. Das ist fast immer auf unbeabsichtigte Fehler oder Defekte zurückzuführen. In einem solchen Fall deaktivieren wir den ursächlichen Service und informieren die Userin darüber. Dass wir hier proaktiv agieren reduziert ebenfalls die Auswirkungen die solche Probleme auf andere Userinnen auf demselben System haben.
In der folgenden Grafik seht ihr eine Übersicht über den Speicher jeder einzelnen VM. Hier fallen uns dann meist außergewöhnliche Anomalien schnell auf.
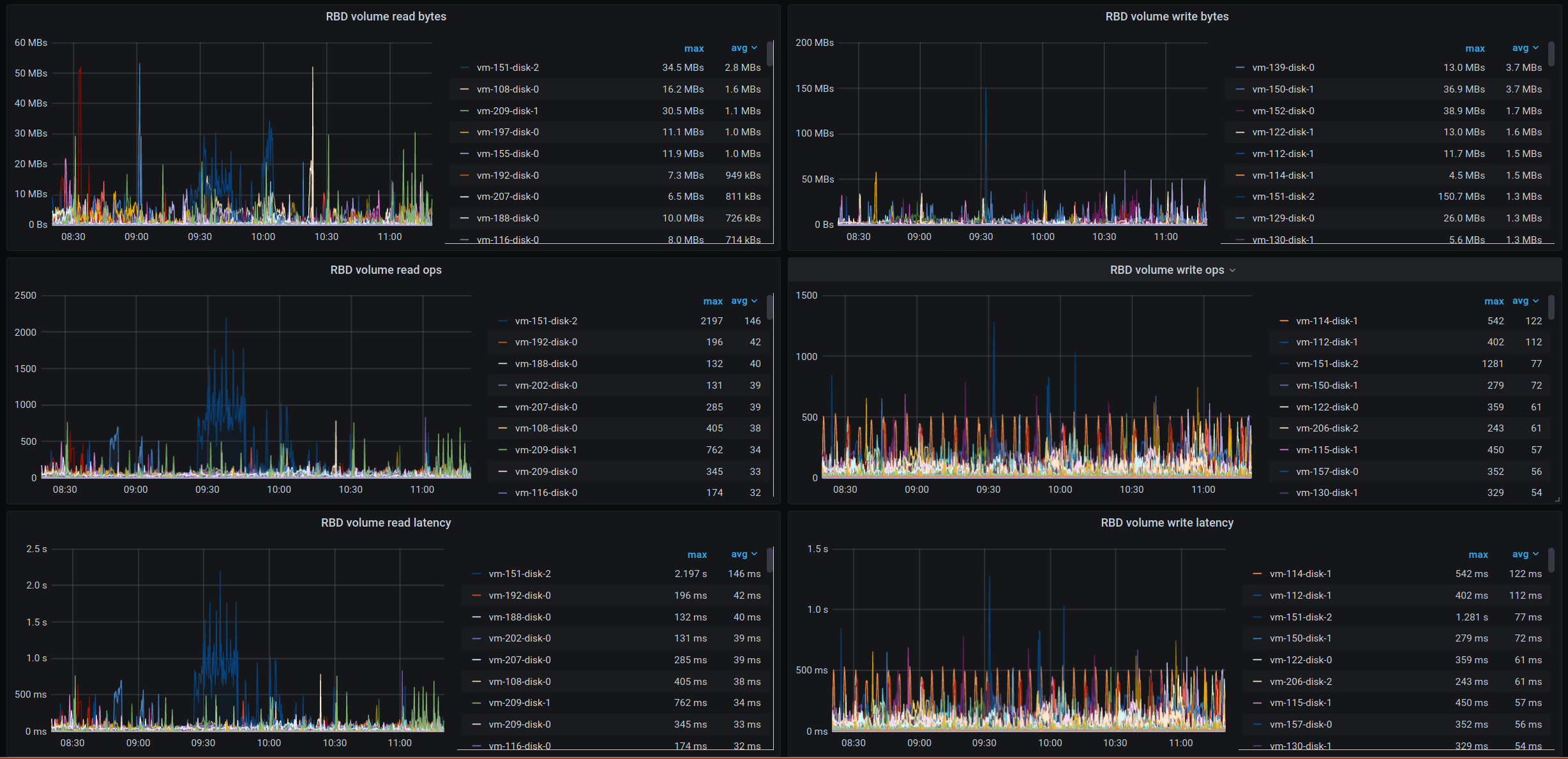
Vor zwei Tagen gab es dann leider eine größere Störung, die mehrere von uns eine Nacht lang in Atem gehalten hat. Immer wieder gab es massenweise Meldungen durch unser Monitoring dass VMs und die Dienste darauf nur sehr schlecht und langsam zu erreichen sind. Angefangen hat es um kurz vor 23 Uhr am Dienstagabend (18.08.2020). Schnell konnten wir OSD.10, also eine Platte in unserem Ceph, als extrem langsam identifizieren und diese wie in einem anderen Beitrag beschrieben für lesende Zugriffe sperren bzw. herab priorisieren. Das hat bis etwa 0:30 Uhr gehalten, dann wurde ich nach nur 30 Minuten Schlaf unsanft vom Uberspace On-Call geweckt und um Unterstützung gebeten. Wieder war alles langsam. Diesmal haben wir die OSD.10 komplett entfernt. Leider haben sich daraufhin noch weitere 3 OSDs als sehr langsam gemeldet und auch diese haben wir in ihrer Priorität reduziert. Gleichzeitig war das Ceph damit beschäftigt, die ca. 3TB an Daten von OSD.10 auf die anderen OSDs zu verteilen. Das alles hat eine Weile gedauert und den Cluster belastet. Um 2:30 Uhr war dann alles schon für längere Zeit wieder so ruhig, dass wir für die Nacht erstmal Pause machen wollten. Das hat bis 7:30 Uhr auch mehr oder weniger funktioniert, dann wurde nochmals ein OSD langsam die wir sperren mussten. Seit dem hat sich das Problem gelöst und alle Latenzen stimmen wieder mit den Erwartungen überein. Was genau die OSDs verlangsamt hat, versuchen wir aktuell noch herauszufinden.
Noch in der Nacht haben wir unser Dashboard um einen Graphen und ein Alerting erweitert, das darauf achtet, ob eine OSD länger als ein paar Minuten langsam ist und dann den On-Call informiert.
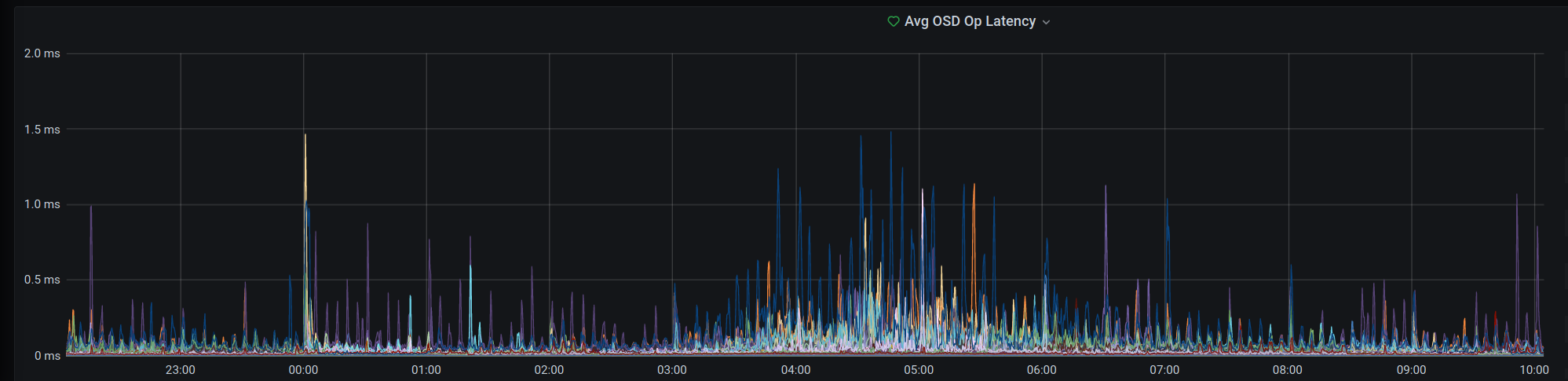
In der obigen Grafik sieht man außerdem eine Häufung von höheren Latenzen nachts zwischen 3 und 6 Uhr morgens. Das ist unser etwas in die Tage gekommenes Backupscript und eine der für uns kommenden Baustellen denn in diesem Zeitfenster bekommen wir noch immer kurze Aussetzer von unserem Monitoring gemeldet. Vorerst wollen wir das Backup der einzelnen VMs weiter über den Tag verteilen um die Last zu verringern. Ganz vermeiden lassen sich die Spikes in der Latenz aktuell noch nicht, aber wir arbeiten dran. Ehrlicherweise nicht nur für die Erreichbarkeit eurer Dienste sondern auch für unsere Nachtruhe und einen tiefen Schlaf ;)
bye bye spinning rust
In den letzten Wochen und Monaten sind wir zu der Erkenntnis gekommen, dass wir aus dem HDD Pool, auch als “spinning rust” bekannt, keine bessere Performance herauskitzeln können. Daher haben wir uns entschieden mittel- und langfristig komplett auf SSD-only für alle Uberspace VMs umzusteigen. Wie schon im vorangegangenen Artikel beschrieben, ist das eine recht kostspielige Angelegenheit, die wir Stück für Stück angehen müssen und für die wir euch - wie immer - keinen festen Zeitplan geben können. VMs die häufiger auffällig sind werden zuerst migriert und neue Uberspace Hosts priorisiert auf dem neuen SSD Storage angelegt - ein weiterer guter Grund für den Umzug von U6 auf U7. Die restlichen VMs werden dann nach und nach migriert, bis wir alles umgezogen haben werden realistischerweise viele Monate vergehen. Allerdings sinkt die Last auf den HDDs auch mit jeder migrierten VM, was die Probleme zusätzlich reduzieren dürfte.
An unserem Preismodell wollen wir trotz der großen Änderungen und Investitionen nicht rütteln, auch wenn wir uns natürlich freuen, wenn du deinen gewählten Preis ab und an überdenkst.
bye bye 10gb Limit
Unter anderem um die Umstellung auf SSDs zu finanzieren, werden wir bald mit einem von vielen von euch lange herbeigesehnten Feature starten: Zubuchbarer Speicher.
Hier schon mal ein paar Eckdaten:
- Wir starten mit der Möglichkeit 10GB dazu buchen zu können
- Perspektivisch können Accounts bis zu 90GB dazu buchen
- Speicher ist buchbar bei einem Wunschpreis von mindestens 5€
- 10GB extra berechnen wir mit 3,50€ pro Monat zusätzlich zum Wunschpreis
- Wir erhöhen die Quota deines Accounts, der Speicher ist für alle Anwendungen nutzbar
Auf eine rostfreie und schnelle Zukunft!