
Ausfälle der Netzwerkanbindung am Standort FRA4
Am letzten Freitagnachmittag (02.09.2022) und am darauffolgenden Samstagabend hat vielleicht bei der ein oder anderen von euch das Monitoring geklingelt, weil euer Uberspace plötzlich nicht mehr erreichbar war. Warum das so war, möchten wir heute versuchen zu erklären.
So wie auch bei euch, hat auch uns unser Monitoring freitags um 14:37 Uhr alarmiert, dass am Standort FRA4 etwas nicht stimmt. Genau genommen haben wir aufgrund der Menge der Meldungen sofort gesehen, dass der Standort scheinbar nicht mehr erreichbar ist, was wir kurz darauf verifizieren konnten.
FRA4 unterscheidet sich dabei etwas von unseren anderen Standorten FRA3 und FRA1, da wir dort aktuell noch keine eigenen Router betreiben. Daher sind wir dort gegenwärtig auf die Gateways unseres RZ-Anbieters angewiesen. Wir planen zwar schon länger auch dort auf eigene Router zu setzen, diese sind jedoch trotz Bestellung im Frühjahr noch immer nicht lieferbar.
Zu diesem Zeitpunkt waren wir bereits zu dritt am Problem dran, eine Person hat sich um die Kommunikation auf Twitter, im Support und auf unserer Statusseite gekümmert; eine weitere darum, über unser Out of Band Management (OOB), das zum Glück noch lief, mehr herauszufinden. Die dritte Person hat unseren RZ-Anbieter kontaktiert und versucht herauszufinden, ob dieser mehr weiß.
Sehr schnell kam von letzterem die Antwort, dass bei ihnen alle Ports Up seien und man keine Fehler erkennen könne. Das war jedoch eine für uns etwas irritierende Antwort, denn auf unseren Switchen waren beide, normal redundanten Verbindungen als Down gemeldet. Jetzt muss man dazu sagen, dass wir an diesen Switchen schon seit längerer Zeit nichts mehr gemacht haben, ein Fehler in der Konfiguration auf unserer Seite also auszuschließen war. Bei der weiteren Analyse konnten wir dann auch schnell feststellen, dass unsere Optik zwar noch lief, wir aber „kein Licht“ mehr ankommen sehen konnten. Wir hatten also einen Signalverlust.
(sw16) #show fiber-ports optics all
Output Input
Port Temp Voltage Current Power Power TX LOS
[C] [Volt] [mA] [dBm] [dBm] Fault
-------- ---- ------- ------- ------- ------- ----- ---
0/49 52.3 3.281 28.0 -2.208 N/A No Yes
0/50 N/A N/A N/A N/A N/A N/A N/A
Temp - Internally measured transceiver temperatures.
Voltage - Internally measured supply voltage.
Current - Measured TX bias current.
Output Power - Measured optical output power relative to 1mW.
Input Power - Measured optical power received relative to 1mW.
TX Fault - Transmitter fault.
LOS - Loss of signal.
Auch sonst sah auf unserer Seite alles gut aus und wir konnten über unseren OOB-Host alle Systeme innerhalb unseres Netzwerks ohne Probleme erreichen. Das sprach nicht nur für ein außerhalb liegendes Problem, sondern bedeutete auch, dass der Cluster mit allen VMs und Diensten einfach weiter lief, wir also nur die Anbindung wiederherstellen mussten.
Über diese Erkenntnisse haben wir dann auch umgehend unseren Provider informiert, der dann überraschend doch bestätigen konnte, dass die Interfaces Down wären und sie ebenfalls zwar eine Sendeleistung, aber keine Empfangsleistung sehen konnten. Außerdem wurde uns bestätigt, dass die beiden Ports zur exakt gleichen Zeit in den Down State gewechselt sind. Da die Switche des Providers und unsere Switche direkt verbunden sind, gab es jetzt zwei Möglichkeiten: Entweder wurden beide Kabel gleichzeitig durchtrennt, oder es lag ein Problem auf einer höheren Ebene vor. Dass es die Kabel sind, da war sich der Techniker des Providers sicher, konnte dann auch recht schnell ausgeschlossen werden, da diese in einer geschützten Kabeltrasse auf dem Boden des Zwischenbodens und zusätzlich von einem dickeren Rohr ummantelt verliefen. Außerdem gibt es noch weitere Fasern im selben Strang, die ebenso nicht betroffen waren.
Blieb also noch ein Problem auf Software-Ebene der Router. Da viel dieser Arbeit parallel geschah, hatten wir in der Zwischenzeit nicht nur unsere Ports deaktiviert und reaktiviert, sondern auch einen der Switche rebooted, um ganz sicher zu sein, dass es nicht ein zufälliger Bug war, der gegen jede Wahrscheinlichkeit auf beiden Systemen zeitgleich aufgetreten ist. Aber auch das hat nicht geholfen. Das Problem lag also ziemlich sicher auf seiten unseres Providers, sodass wir nichts weiter machen konnten. Inzwischen bestätigte uns dieser auch, dass er auf den Interfaces vor dem Ausfall „viele“ Fehler sehen würde.
Leider - und das war für uns sehr unerfreulich - war der Techniker, der sich besonders gut mit den Routern auskennt, nicht erreichbar, da er, so die Spekulation des Technikers, mit dem wir telefonisch im ständigen Kontakt standen, gerade wohl im Flugzeug saß. Uns blieb also nichts anderes übrig als zu warten und zu diesem Zeitpunkt waren wir schon bei fast 90 Minuten Downtime. Puh!
Nach einer weiteren Stunde um 17:13 Uhr konnten wir dann in unserem Monitoring und einem parallel laufenden MTR beobachten, dass die Verbindungen wieder da waren.
Im Nachgang haben wir dann von unserem Provider die Information erhalten, dass dieser einen außergewöhnlich hohen Multicast Traffic auf unseren Ports beobachtet hat, was bei diesen die Multicast Storm Control aktiviert und damit die Ports deaktiviert hat. Multicast-Stürme sind, ähnlich wie Broadcast-Stürme, Fehlfunktionen eines Netzwerks, die zu einer Überlastung des selbigen führen können.
Dass über dieses Feature bei unserem Provider scheinbar nicht ausreichend Wissen existierte und es auch kein Monitoring gab, wurde dann wohl umgehend angegangen, sodass der zweite Ausfall gegen 22 Uhr am Samstag dann innerhalb von 10 Minuten behoben werden konnte. Warum die Ports nicht wie es eigentlich sein sollte nach dem extrem kurzen Peak wieder automatisch aktiviert wurden, ist bis zur Stunde unklar.
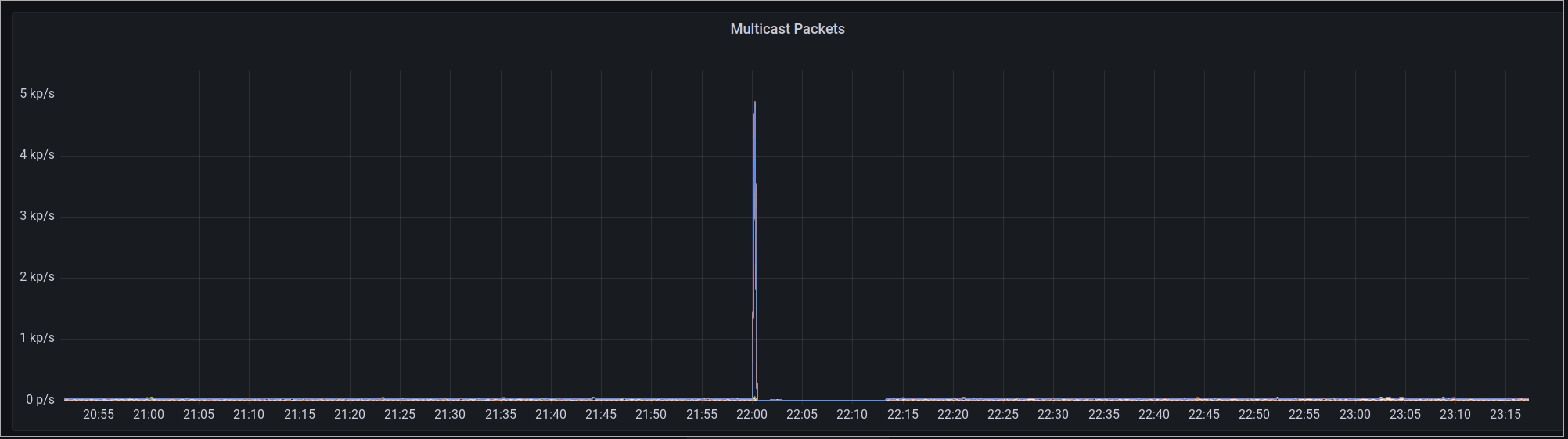 Graph der um 22 Uhr einen starken Peak von ca. 5000 Multicast Paketen pro Sekunde ZeigtAuch wir hatten nämlich in der Zwischenzeit unser Monitoring erweitert und die Switche am Standort FRA4 in unser SNMP-Monitoring aufgenommen. Daher konnten wir, wie im obigen Bild zu erkennen, die Störung diesmal nachvollziehen. Bisher war dies an FRA4 nicht der Fall da, wir aufgrund der anderen Netzarchitektur dort kein von unserem Monitoring direkt erreichbares Management-Netz betreiben.
Graph der um 22 Uhr einen starken Peak von ca. 5000 Multicast Paketen pro Sekunde ZeigtAuch wir hatten nämlich in der Zwischenzeit unser Monitoring erweitert und die Switche am Standort FRA4 in unser SNMP-Monitoring aufgenommen. Daher konnten wir, wie im obigen Bild zu erkennen, die Störung diesmal nachvollziehen. Bisher war dies an FRA4 nicht der Fall da, wir aufgrund der anderen Netzarchitektur dort kein von unserem Monitoring direkt erreichbares Management-Netz betreiben.
Zusätzlich zu den einfachen Metriken haben wir nun auch Alerts, die solches Fehlverhalten und das Ausfallen einzelner Ports besser überwachen. Trotz der Metriken konnten wir den Multicast Peak nicht eindeutig zu einem Ursprung zurückverfolgen, da einige Switche auch nach dieser Änderung noch Probleme mit dem Management-Netz machen und so nicht im Monitoring auftauchen, daran arbeiten wir aktuell noch.